python_25 : Data Preprocessing(LabelEncoder,OneHotEncoder, Feature scaling)
python_25 : Data Preprocessing(LabelEncoder,OneHotEncoder,Feature scaling)
문자 인코딩(영어: character encoding), 줄여서 인코딩은 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 말한다.
인코딩과 디코딩 (Encoding & Decoding)
컴퓨터는 문자를 인식할 수 없기 때문에 숫자로 변환되어 저장된다.
변환해주기 위해서는 기준이 있어야하는데 이것을 문자 코드라고 하며 대표적으로 ASCII코드 또는 유니코드가 있다.
이렇게 문자 코드를 기준으로 문자를 코드로 변환하는 것을 문자 인코딩(encoding) 이라하고 코드를 문자로 변환하는 것을 문자 디코딩(decoding) 이라고 한다.
기본적으로 사이킷런의 머신러닝 알고리즘은 문자열 값을 입력 값으로 허락하지 않는다.
그렇기 때문에 모든 문자열 값들을 숫자 형으로 인코딩하는 전처리 작업 후에 머신러닝 모델에 학습을 시켜야한다.
이렇게 인코딩 하는 방식에는 크게 레이블 인코딩(Lable encoding)과 원-핫 인코딩(One Hot Encoding)이 있다.
레이블 인코딩과 원-핫 인코딩(LabelEncoding&OneHotEncoding)
레이블인코딩(LabelEncoding)은 문자형태의 데이터로 구성된 피쳐를 수치화한다. 즉,글자를 숫자로 바꿔주는것이다.
레이블 인코딩은 간단하게 문자열 값을 숫자형 카테고리 값으로 변환하지만 숫자 값의 크고 작음에 대한 특성때문에 몇몇 ML 알고리즘에는 이를 적용할 경우 예측 성능이 떨어지는 경우가 발생할 수 있다. 즉, 숫자 변환 값은 단순 코드이지 숫자 값에 따른 순서나 중요도로 인식되면 안된다. 그래서 레이블 인코딩은 선형 회귀와 같은 ML 알고리즘에는 적용하지 않아야 한다.
원-핫 인코딩(OneHotEncoder)은 숫자로 표현된 범주형 데이터를 인코딩한다. Loss를 계산하기 쉽게 만들어 주기 위해 벡터의 딱 한개의 요소만 1나머지 요소는 모두 0인 벡터로 만들어 주는것이다. 이 값들이 학습(Training)시킬 y값 즉, Label 값(supervised learning)이라면, 이 값들은 벡터로 바뀌어야 한다
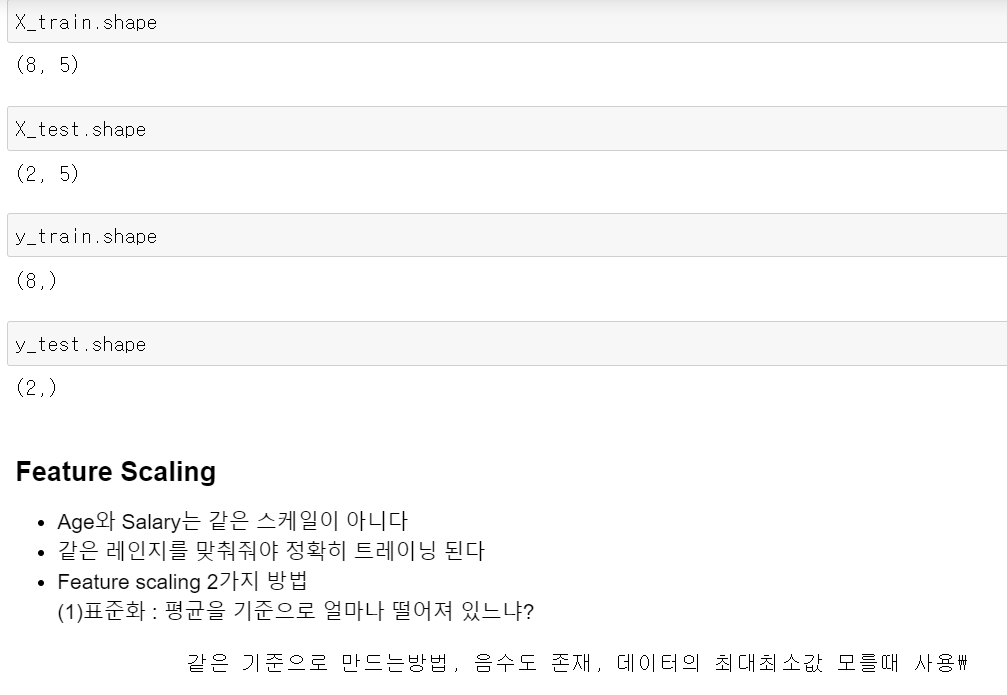
Feature Scaling
Age는 27~50, salary는 40k ~ 90k, Age와 salary는 같은 스케일이 아니다
유클리드 거리(Euclidean distance)로 오차를 줄여 나가는데, 하나의 변수는 오차가 크고 하나의 변수는 오차가 작으면 나중에 오차를 수정할때 편중하게 된다 따라서 값의 레인지를 맞춰줘야 정확히 트레이닝 된다
Feature scaling 2가지 방법
. 표준화
평균을 기준으로 얼마나 떨어져 있느냐? 같은 기준으로 만드는방법이다.
음수도 존재, 데이터의 최대최소값 모를때 사용한다.
. 정규화
0 ~ 1사이를 맞추는것, 데이터의 위치 비교가 가능하다
데이터의 최대최소값 일때 사용한다.
학습 데이터와 테스트 데이터 변환시 주의사항
StandardScaler나 MinMaxScaler와 같은 Scaler 객체를 이용해 변환 시 fit(), transform(), fit_transform()메소드를 이용한다.
. fit() : 데이터 변환을 위한 기준 정보 설정
. transform(): 설정된 정보를 이용해 데이터를 변환
. fit_transform() : 두가지를 한번에 적용하는 기능을 수행
학습 데이터 세트로 fit()과 transform()을 적용하면 테스트 데이터 세트로는 다시 fit()을 수행하지 않고 학습 데이터 세트로 수행한 결과를 이용해 transform() 변환을 적용해야 한다. 만약 테스트 데이터로 다시 새로운 스케일링 기준 정보를 만들게 되면 학습 데이터와 테스트 데이터의 스케일링 기준 정보가 달라져 올바른 예측 결과를 도출하지 못할 수 있다.